Proteins (10)
BCBruno Cucco
id: pale-vole-vine
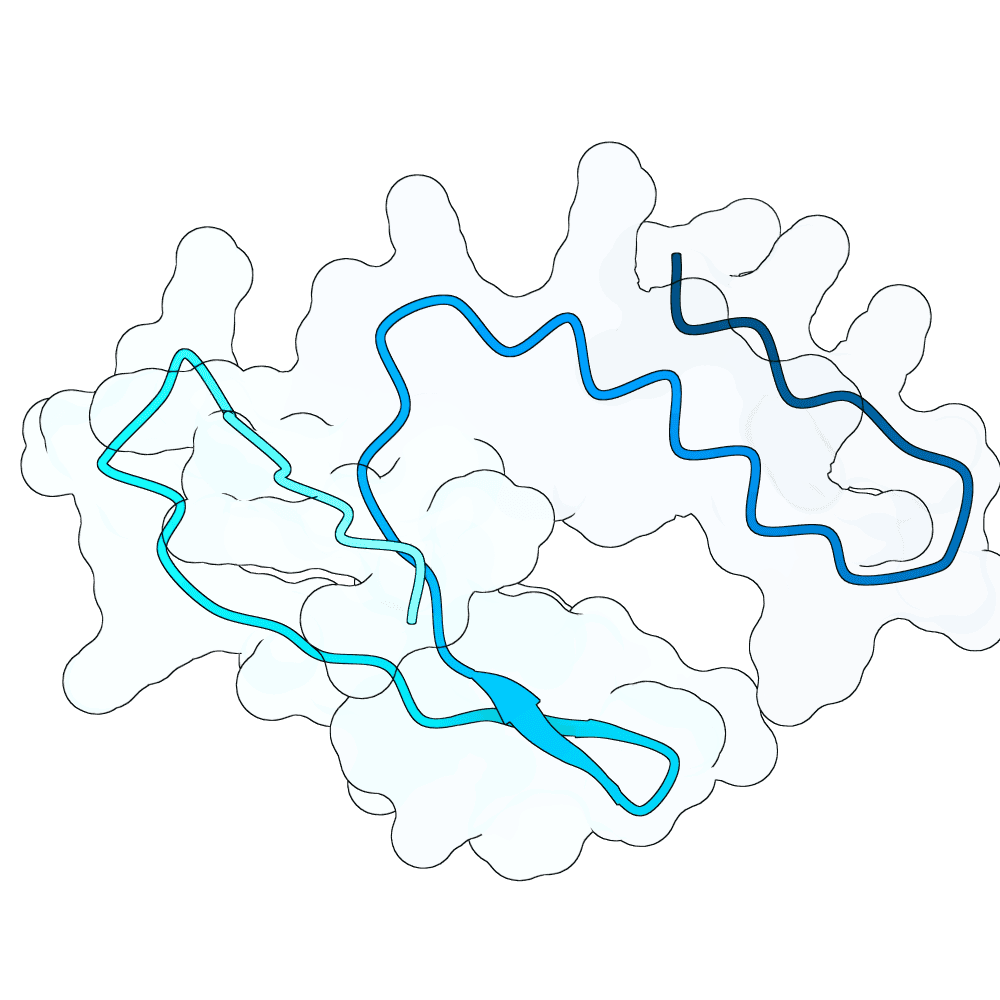
Target
Nipah Virus Glycoprotein G
Binding
None
pLDDT
33.26
Expressed
False
Mol. Weight
6.7 kDa
AA Length
52
BCBruno Cucco
id: soft-shark-clay
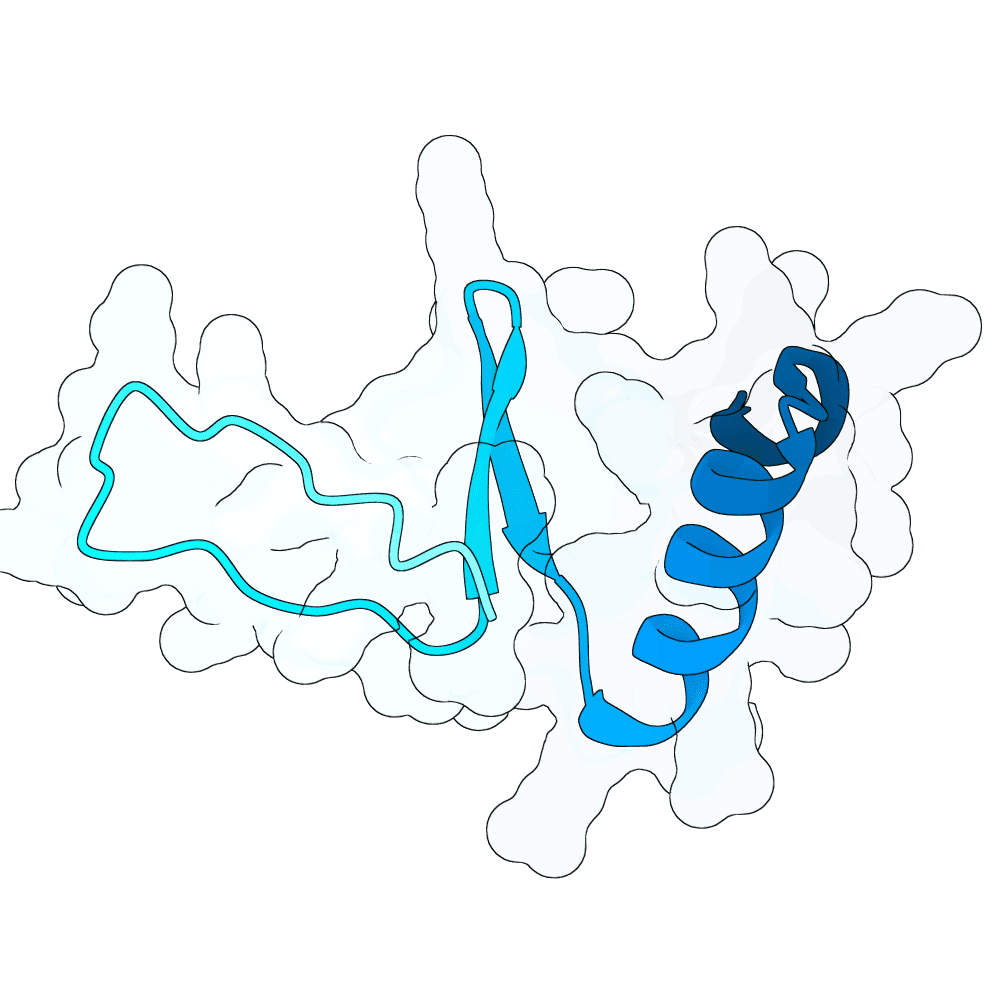
Target
Nipah Virus Glycoprotein G
Binding
None
pLDDT
44.90
Expressed
True
Mol. Weight
6.1 kDa
AA Length
51
BCBruno Cucco
id: ivory-goat-sand
Target
Nipah Virus Glycoprotein G
Binding
None
pLDDT
67.33
Expressed
True
Mol. Weight
6.1 kDa
AA Length
51
BCBruno Cucco
id: green-mole-clay

Target
Nipah Virus Glycoprotein G
Binding
None
pLDDT
43.76
Expressed
True
Mol. Weight
6.5 kDa
AA Length
51
BCBruno Cucco
id: amber-heron-pine

Target
Nipah Virus Glycoprotein G
Binding
None
pLDDT
48.57
Expressed
False
Mol. Weight
6.4 kDa
AA Length
51
BCBruno Cucco
id: noble-jaguar-ash
Target
Nipah Virus Glycoprotein G
Binding
None
pLDDT
36.79
Expressed
True
Mol. Weight
6.4 kDa
AA Length
51
BCBruno Cucco
id: soft-fox-ruby

Target
Nipah Virus Glycoprotein G
Binding
None
pLDDT
49.12
Expressed
True
Mol. Weight
6.4 kDa
AA Length
52
BCBruno Cucco
id: mellow-otter-leaf

Target
Nipah Virus Glycoprotein G
Binding
None
pLDDT
48.30
Expressed
True
Mol. Weight
6.2 kDa
AA Length
51
BCBruno Cucco
id: gentle-moth-lotus
Target
Nipah Virus Glycoprotein G
Binding
None
pLDDT
48.67
Expressed
True
Mol. Weight
6.5 kDa
AA Length
51
BCBruno Cucco
id: swift-seal-reed
Target
Nipah Virus Glycoprotein G
Binding
None
pLDDT
51.21
Expressed
True
Mol. Weight
6.1 kDa
AA Length
51